1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
|
'''
@File : 感知机.ipynb
@Time : 2025/03/24 21:29:44
@Author : Neutrin
'''
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
n_samples_neg = 100
X_neg = np.random.normal(loc=[-2, -2], scale=1.0, size=(n_samples_neg, 2))
y_neg = np.zeros(n_samples_neg)
n_samples_pos = 100
X_pos = np.random.normal(loc=[2, 2], scale=1.0, size=(n_samples_pos, 2))
y_pos = np.ones(n_samples_pos)
X = np.vstack((X_neg, X_pos))
y = np.hstack((y_neg, y_pos))
plt.figure(figsize=(8, 6))
plt.scatter(X_neg[:, 0], X_neg[:, 1], c='blue', marker='o', label='Class 0')
plt.scatter(X_pos[:, 0], X_pos[:, 1], c='red', marker='x', label='Class 1')
plt.title('Perceptron Training Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.grid(True)
plt.show()
print(f"Dataset shape: X: {X.shape}, y: {y.shape}")
def out(x, w, b):
return np.sign(np.dot(x, w) + b)
class Perceptron:
def __init__(self, learning_rate=0.01, max_iterations=1000):
self.learning_rate = learning_rate
self.max_iterations = max_iterations
self.w = None
self.b = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.w = np.zeros(n_features)
self.b = 0
y_transformed = np.where(y == 0, -1, 1)
for _ in range(self.max_iterations):
misclassified = 0
for idx, x_i in enumerate(X):
y_i = y_transformed[idx]
if y_i * (np.dot(x_i, self.w) + self.b) <= 0:
self.w += self.learning_rate * y_i * x_i
self.b += self.learning_rate * y_i
misclassified += 1
if misclassified == 0:
break
return self
def predict(self, X):
return np.where(np.sign(np.dot(X, self.w) + self.b) == -1, 0, 1)
def score(self, X, y):
y_pred = self.predict(X)
return np.mean(y_pred == y)
def decision_boundary(self):
return self.w, self.b
perceptron = Perceptron(learning_rate=0.01, max_iterations=1000)
perceptron.fit(X, y)
accuracy = perceptron.score(X, y)
print(f"Accuracy: {accuracy:.4f}")
w, b = perceptron.decision_boundary()
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = np.sign(np.dot(np.c_[xx.ravel(), yy.ravel()], w) + b).reshape(xx.shape)
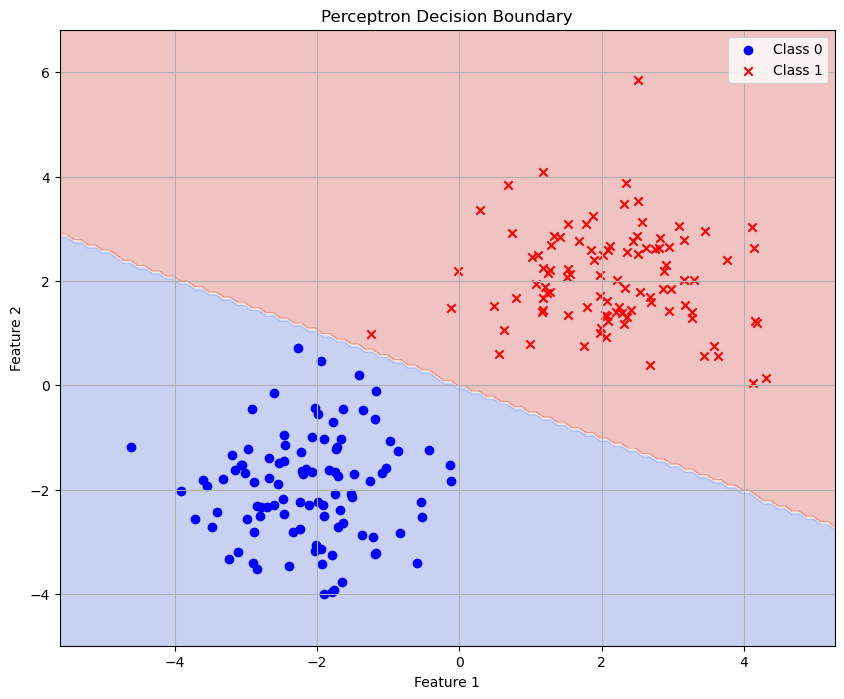
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.coolwarm)
plt.scatter(X_neg[:, 0], X_neg[:, 1], c='blue', marker='o', label='Class 0')
plt.scatter(X_pos[:, 0], X_pos[:, 1], c='red', marker='x', label='Class 1')
plt.title('Perceptron Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.grid(True)
plt.show()
PYTHON
|